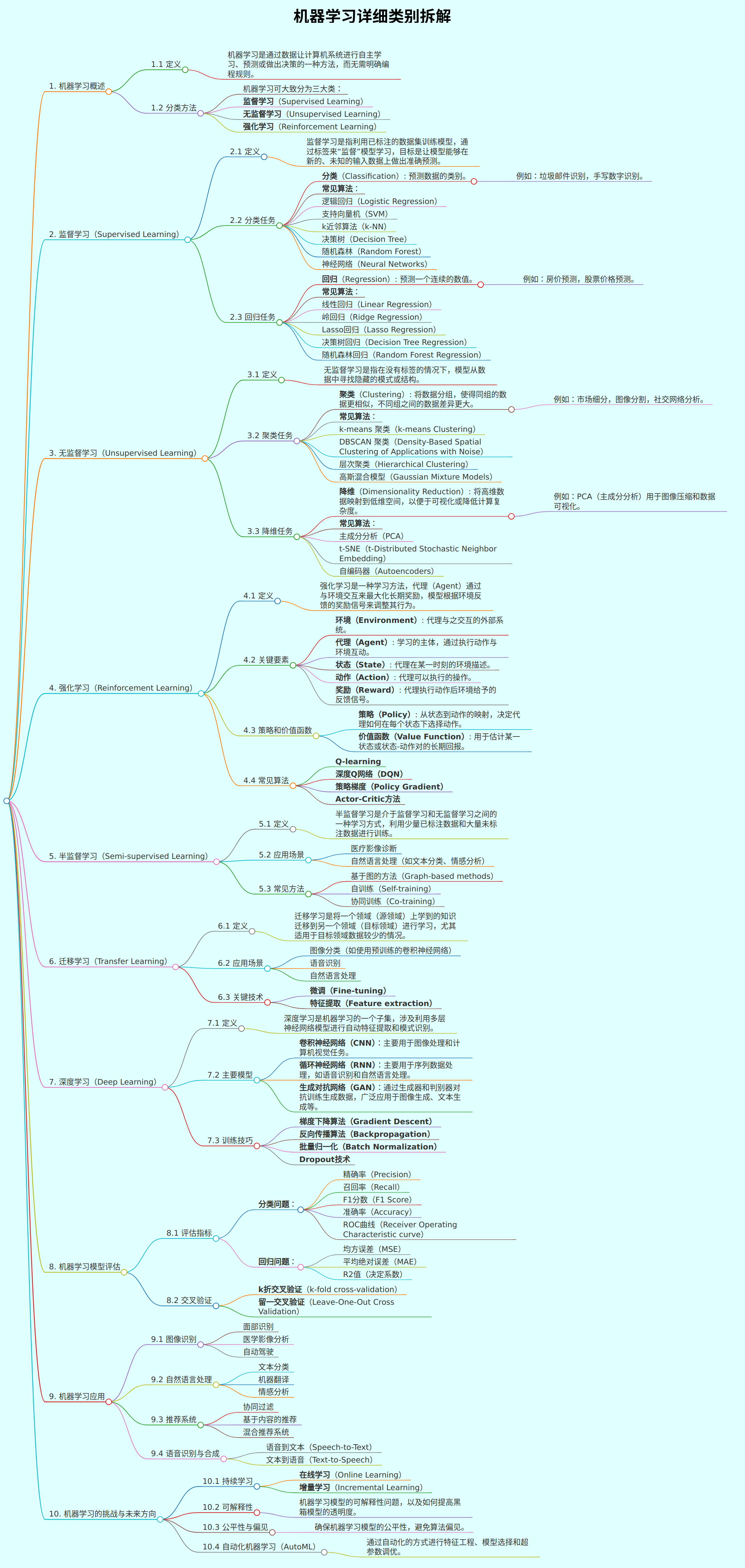
# 机器学习详细类别拆解
- 机器学习是人工智能领域的一个核心子领域,广泛应用于自动化决策、预测、分析等方面。为了帮助理解机器学习的核心概念,以下是对机器学习的详细拆解,以便更好地理解和记忆。
## 1. 机器学习概述
### 1.1 定义
- 机器学习是通过数据让计算机系统进行自主学习、预测或做出决策的一种方法,而无需明确编程规则。
### 1.2 分类方法
- 机器学习可大致分为三大类:
- **监督学习**(Supervised Learning)
- **无监督学习**(Unsupervised Learning)
- **强化学习**(Reinforcement Learning)
---
## 2. 监督学习(Supervised Learning)
### 2.1 定义
- 监督学习是指利用已标注的数据集训练模型,通过标签来“监督”模型学习,目标是让模型能够在新的、未知的输入数据上做出准确预测。
### 2.2 分类任务
- **分类**(Classification): 预测数据的类别。
- 例如:垃圾邮件识别,手写数字识别。
- **常见算法**:
- 逻辑回归(Logistic Regression)
- 支持向量机(SVM)
- k近邻算法(k-NN)
- 决策树(Decision Tree)
- 随机森林(Random Forest)
- 神经网络(Neural Networks)
### 2.3 回归任务
- **回归**(Regression): 预测一个连续的数值。
- 例如:房价预测,股票价格预测。
- **常见算法**:
- 线性回归(Linear Regression)
- 岭回归(Ridge Regression)
- Lasso回归(Lasso Regression)
- 决策树回归(Decision Tree Regression)
- 随机森林回归(Random Forest Regression)
---
## 3. 无监督学习(Unsupervised Learning)
### 3.1 定义
- 无监督学习是指在没有标签的情况下,模型从数据中寻找隐藏的模式或结构。
### 3.2 聚类任务
- **聚类**(Clustering): 将数据分组,使得同组的数据更相似,不同组之间的数据差异更大。
- 例如:市场细分,图像分割,社交网络分析。
- **常见算法**:
- k-means 聚类(k-means Clustering)
- DBSCAN 聚类(Density-Based Spatial Clustering of Applications with Noise)
- 层次聚类(Hierarchical Clustering)
- 高斯混合模型(Gaussian Mixture Models)
### 3.3 降维任务
- **降维**(Dimensionality Reduction): 将高维数据映射到低维空间,以便于可视化或降低计算复杂度。
- 例如:PCA(主成分分析)用于图像压缩和数据可视化。
- **常见算法**:
- 主成分分析(PCA)
- t-SNE(t-Distributed Stochastic Neighbor Embedding)
- 自编码器(Autoencoders)
---
## 4. 强化学习(Reinforcement Learning)
### 4.1 定义
- 强化学习是一种学习方法,代理(Agent)通过与环境交互来最大化长期奖励,模型根据环境反馈的奖励信号来调整其行为。
### 4.2 关键要素
- **环境(Environment)**: 代理与之交互的外部系统。
- **代理(Agent)**: 学习的主体,通过执行动作与环境互动。
- **状态(State)**: 代理在某一时刻的环境描述。
- **动作(Action)**: 代理可以执行的操作。
- **奖励(Reward)**: 代理执行动作后环境给予的反馈信号。
### 4.3 策略和价值函数
- **策略(Policy)**: 从状态到动作的映射,决定代理如何在每个状态下选择动作。
- **价值函数(Value Function)**: 用于估计某一状态或状态-动作对的长期回报。
### 4.4 常见算法
- **Q-learning**
- **深度Q网络(DQN)**
- **策略梯度(Policy Gradient)**
- **Actor-Critic方法**
---
## 5. 半监督学习(Semi-supervised Learning)
### 5.1 定义
- 半监督学习是介于监督学习和无监督学习之间的一种学习方式,利用少量已标注数据和大量未标注数据进行训练。
### 5.2 应用场景
- 医疗影像诊断
- 自然语言处理(如文本分类、情感分析)
### 5.3 常见方法
- 基于图的方法(Graph-based methods)
- 自训练(Self-training)
- 协同训练(Co-training)
---
## 6. 迁移学习(Transfer Learning)
### 6.1 定义
- 迁移学习是将一个领域(源领域)上学到的知识迁移到另一个领域(目标领域)进行学习,尤其适用于目标领域数据较少的情况。
### 6.2 应用场景
- 图像分类(如使用预训练的卷积神经网络)
- 语音识别
- 自然语言处理
### 6.3 关键技术
- **微调(Fine-tuning)**
- **特征提取(Feature extraction)**
---
## 7. 深度学习(Deep Learning)
### 7.1 定义
- 深度学习是机器学习的一个子集,涉及利用多层神经网络模型进行自动特征提取和模式识别。
### 7.2 主要模型
- **卷积神经网络(CNN)**:主要用于图像处理和计算机视觉任务。
- **循环神经网络(RNN)**:主要用于序列数据处理,如语音识别和自然语言处理。
- **生成对抗网络(GAN)**:通过生成器和判别器对抗训练生成数据,广泛应用于图像生成、文本生成等。
### 7.3 训练技巧
- **梯度下降算法(Gradient Descent)**
- **反向传播算法(Backpropagation)**
- **批量归一化(Batch Normalization)**
- **Dropout技术**
---
## 8. 机器学习模型评估
### 8.1 评估指标
- **分类问题**:
- 精确率(Precision)
- 召回率(Recall)
- F1分数(F1 Score)
- 准确率(Accuracy)
- ROC曲线(Receiver Operating Characteristic curve)
- **回归问题**:
- 均方误差(MSE)
- 平均绝对误差(MAE)
- R2值(决定系数)
### 8.2 交叉验证
- **k折交叉验证**(k-fold cross-validation)
- **留一交叉验证**(Leave-One-Out Cross Validation)
---
## 9. 机器学习应用
### 9.1 图像识别
- 面部识别
- 医学影像分析
- 自动驾驶
### 9.2 自然语言处理
- 文本分类
- 机器翻译
- 情感分析
### 9.3 推荐系统
- 协同过滤
- 基于内容的推荐
- 混合推荐系统
### 9.4 语音识别与合成
- 语音到文本(Speech-to-Text)
- 文本到语音(Text-to-Speech)
---
## 10. 机器学习的挑战与未来方向
### 10.1 持续学习
- **在线学习**(Online Learning)
- **增量学习**(Incremental Learning)
### 10.2 可解释性
- 机器学习模型的可解释性问题,以及如何提高黑箱模型的透明度。
### 10.3 公平性与偏见
- 确保机器学习模型的公平性,避免算法偏见。
### 10.4 自动化机器学习(AutoML)
- 通过自动化的方式进行特征工程、模型选择和超参数调优。
---
以上是机器学习的详细类别拆解,涵盖了基本概念、技术、应用和未来趋势。
复制内容
下载markdown文件
在线编辑