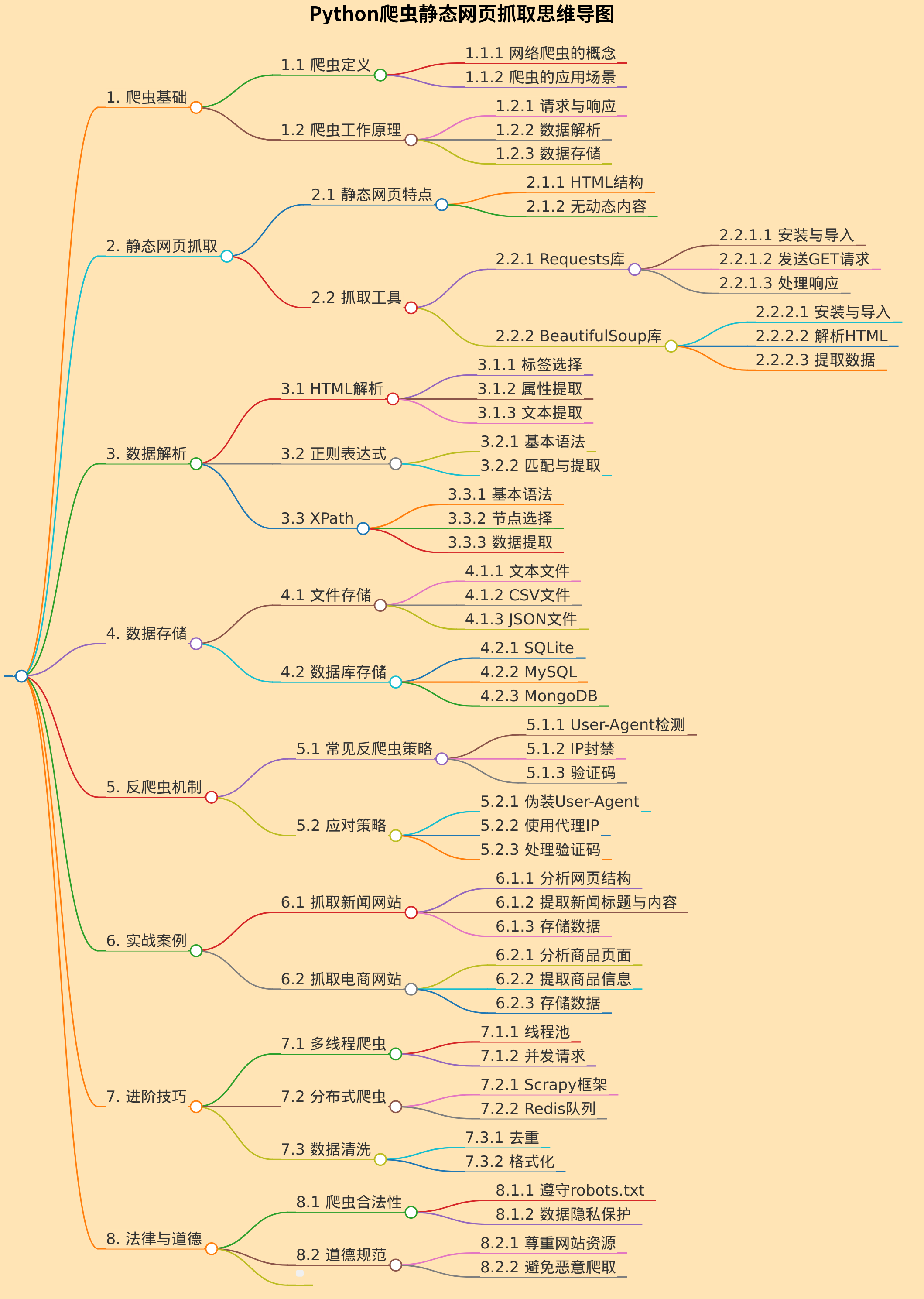
- ```markdown
# Python爬虫静态网页抓取思维导图
## 1. 爬虫基础
- 1.1 爬虫定义
- 1.1.1 网络爬虫的概念
- 1.1.2 爬虫的应用场景
- 1.2 爬虫工作原理
- 1.2.1 请求与响应
- 1.2.2 数据解析
- 1.2.3 数据存储
## 2. 静态网页抓取
- 2.1 静态网页特点
- 2.1.1 HTML结构
- 2.1.2 无动态内容
- 2.2 抓取工具
- 2.2.1 Requests库
- 2.2.1.1 安装与导入
- 2.2.1.2 发送GET请求
- 2.2.1.3 处理响应
- 2.2.2 BeautifulSoup库
- 2.2.2.1 安装与导入
- 2.2.2.2 解析HTML
- 2.2.2.3 提取数据
## 3. 数据解析
- 3.1 HTML解析
- 3.1.1 标签选择
- 3.1.2 属性提取
- 3.1.3 文本提取
- 3.2 正则表达式
- 3.2.1 基本语法
- 3.2.2 匹配与提取
- 3.3 XPath
- 3.3.1 基本语法
- 3.3.2 节点选择
- 3.3.3 数据提取
## 4. 数据存储
- 4.1 文件存储
- 4.1.1 文本文件
- 4.1.2 CSV文件
- 4.1.3 JSON文件
- 4.2 数据库存储
- 4.2.1 SQLite
- 4.2.2 MySQL
- 4.2.3 MongoDB
## 5. 反爬虫机制
- 5.1 常见反爬虫策略
- 5.1.1 User-Agent检测
- 5.1.2 IP封禁
- 5.1.3 验证码
- 5.2 应对策略
- 5.2.1 伪装User-Agent
- 5.2.2 使用代理IP
- 5.2.3 处理验证码
## 6. 实战案例
- 6.1 抓取新闻网站
- 6.1.1 分析网页结构
- 6.1.2 提取新闻标题与内容
- 6.1.3 存储数据
- 6.2 抓取电商网站
- 6.2.1 分析商品页面
- 6.2.2 提取商品信息
- 6.2.3 存储数据
## 7. 进阶技巧
- 7.1 多线程爬虫
- 7.1.1 线程池
- 7.1.2 并发请求
- 7.2 分布式爬虫
- 7.2.1 Scrapy框架
- 7.2.2 Redis队列
- 7.3 数据清洗
- 7.3.1 去重
- 7.3.2 格式化
## 8. 法律与道德
- 8.1 爬虫合法性
- 8.1.1 遵守robots.txt
- 8.1.2 数据隐私保护
- 8.2 道德规范
- 8.2.1 尊重网站资源
- 8.2.2 避免恶意爬取
- ```
复制内容
下载markdown文件
在线编辑