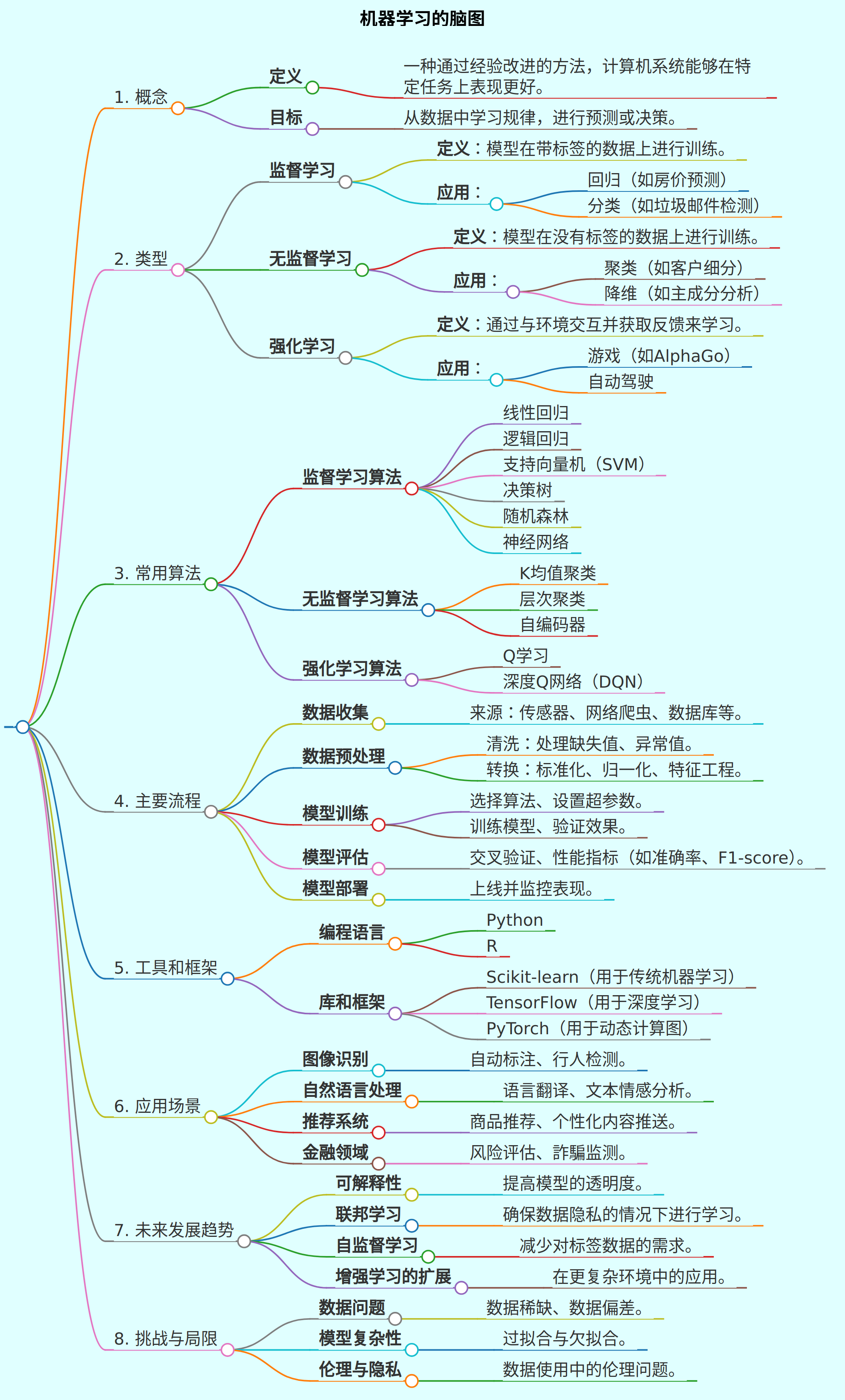
# 机器学习的脑图
## 1. 概念
- **定义**
- 一种通过经验改进的方法,计算机系统能够在特定任务上表现更好。
- **目标**
- 从数据中学习规律,进行预测或决策。
## 2. 类型
- **监督学习**
- **定义**:模型在带标签的数据上进行训练。
- **应用**:
- 回归(如房价预测)
- 分类(如垃圾邮件检测)
- **无监督学习**
- **定义**:模型在没有标签的数据上进行训练。
- **应用**:
- 聚类(如客户细分)
- 降维(如主成分分析)
- **强化学习**
- **定义**:通过与环境交互并获取反馈来学习。
- **应用**:
- 游戏(如AlphaGo)
- 自动驾驶
## 3. 常用算法
- **监督学习算法**
- 线性回归
- 逻辑回归
- 支持向量机(SVM)
- 决策树
- 随机森林
- 神经网络
- **无监督学习算法**
- K均值聚类
- 层次聚类
- 自编码器
- **强化学习算法**
- Q学习
- 深度Q网络(DQN)
## 4. 主要流程
- **数据收集**
- 来源:传感器、网络爬虫、数据库等。
- **数据预处理**
- 清洗:处理缺失值、异常值。
- 转换:标准化、归一化、特征工程。
- **模型训练**
- 选择算法、设置超参数。
- 训练模型、验证效果。
- **模型评估**
- 交叉验证、性能指标(如准确率、F1-score)。
- **模型部署**
- 上线并监控表现。
## 5. 工具和框架
- **编程语言**
- Python
- R
- **库和框架**
- Scikit-learn(用于传统机器学习)
- TensorFlow(用于深度学习)
- PyTorch(用于动态计算图)
## 6. 应用场景
- **图像识别**
- 自动标注、行人检测。
- **自然语言处理**
- 语言翻译、文本情感分析。
- **推荐系统**
- 商品推荐、个性化内容推送。
- **金融领域**
- 风险评估、詐騙监测。
## 7. 未来发展趋势
- **可解释性**
- 提高模型的透明度。
- **联邦学习**
- 确保数据隐私的情况下进行学习。
- **自监督学习**
- 减少对标签数据的需求。
- **增强学习的扩展**
- 在更复杂环境中的应用。
## 8. 挑战与局限
- **数据问题**
- 数据稀缺、数据偏差。
- **模型复杂性**
- 过拟合与欠拟合。
- **伦理与隐私**
- 数据使用中的伦理问题。
复制内容
下载markdown文件
在线编辑