- ```markdown
# H200芯片介绍
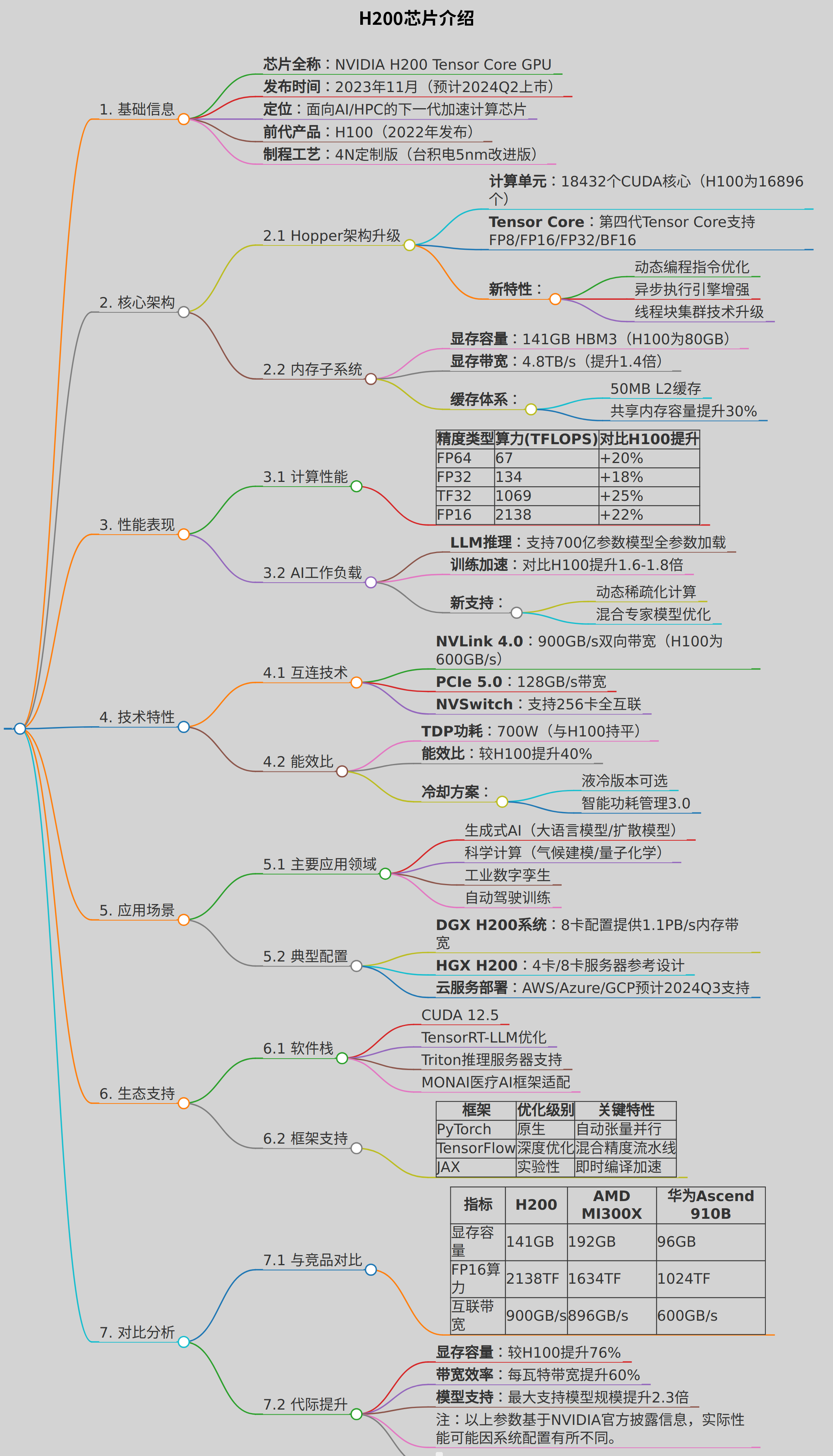
## 1. 基础信息
- **芯片全称**:NVIDIA H200 Tensor Core GPU
- **发布时间**:2023年11月(预计2024Q2上市)
- **定位**:面向AI/HPC的下一代加速计算芯片
- **前代产品**:H100(2022年发布)
- **制程工艺**:4N定制版(台积电5nm改进版)
## 2. 核心架构
### 2.1 Hopper架构升级
- **计算单元**:18432个CUDA核心(H100为16896个)
- **Tensor Core**:第四代Tensor Core支持FP8/FP16/FP32/BF16
- **新特性**:
- 动态编程指令优化
- 异步执行引擎增强
- 线程块集群技术升级
### 2.2 内存子系统
- **显存容量**:141GB HBM3(H100为80GB)
- **显存带宽**:4.8TB/s(提升1.4倍)
- **缓存体系**:
- 50MB L2缓存
- 共享内存容量提升30%
## 3. 性能表现
### 3.1 计算性能
| 精度类型 | 算力(TFLOPS) | 对比H100提升 |
|---------|-------------|-------------|
| FP64 | 67 | +20% |
| FP32 | 134 | +18% |
| TF32 | 1069 | +25% |
| FP16 | 2138 | +22% |
### 3.2 AI工作负载
- **LLM推理**:支持700亿参数模型全参数加载
- **训练加速**:对比H100提升1.6-1.8倍
- **新支持**:
- 动态稀疏化计算
- 混合专家模型优化
## 4. 技术特性
### 4.1 互连技术
- **NVLink 4.0**:900GB/s双向带宽(H100为600GB/s)
- **PCIe 5.0**:128GB/s带宽
- **NVSwitch**:支持256卡全互联
### 4.2 能效比
- **TDP功耗**:700W(与H100持平)
- **能效比**:较H100提升40%
- **冷却方案**:
- 液冷版本可选
- 智能功耗管理3.0
## 5. 应用场景
### 5.1 主要应用领域
- 生成式AI(大语言模型/扩散模型)
- 科学计算(气候建模/量子化学)
- 工业数字孪生
- 自动驾驶训练
### 5.2 典型配置
- **DGX H200系统**:8卡配置提供1.1PB/s内存带宽
- **HGX H200**:4卡/8卡服务器参考设计
- **云服务部署**:AWS/Azure/GCP预计2024Q3支持
## 6. 生态支持
### 6.1 软件栈
- CUDA 12.5
- TensorRT-LLM优化
- Triton推理服务器支持
- MONAI医疗AI框架适配
### 6.2 框架支持
| 框架 | 优化级别 | 关键特性 |
|------------|----------|----------|
| PyTorch | 原生 | 自动张量并行 |
| TensorFlow | 深度优化 | 混合精度流水线 |
| JAX | 实验性 | 即时编译加速 |
## 7. 对比分析
### 7.1 与竞品对比
| 指标 | H200 | AMD MI300X | 华为Ascend 910B |
|------------|---------|------------|-----------------|
| 显存容量 | 141GB | 192GB | 96GB |
| FP16算力 | 2138TF | 1634TF | 1024TF |
| 互联带宽 | 900GB/s | 896GB/s | 600GB/s |
### 7.2 代际提升
- **显存容量**:较H100提升76%
- **带宽效率**:每瓦特带宽提升60%
- **模型支持**:最大支持模型规模提升2.3倍
- 注:以上参数基于NVIDIA官方披露信息,实际性能可能因系统配置有所不同。
- ```
复制内容
下载markdown文件
在线编辑